
Lorem ipsum dolor sit amet consectetur pellentesque.
12 Mar, 2024



During the last Deploying Databases post, we learnt about creating tables, why every piece of data should be unique and how to use relationships between tables to stop repetitive and redundant data.
If you haven’t read The Set Up post already, you probably should. It introduces concepts we take further in this post and, most importantly, introduces our protagonist, Jim. Jim runs a cake business and bakes all manner of cakes for his friends, family and people in the local area.
Well, it seems that Jim’s new database has helped him to build his customer base up from 20 orders a week to in excess of 500. Besides bringing in some staff to help him out in his cake-y endeavours, he needs to better manage his data and develop his database even more.
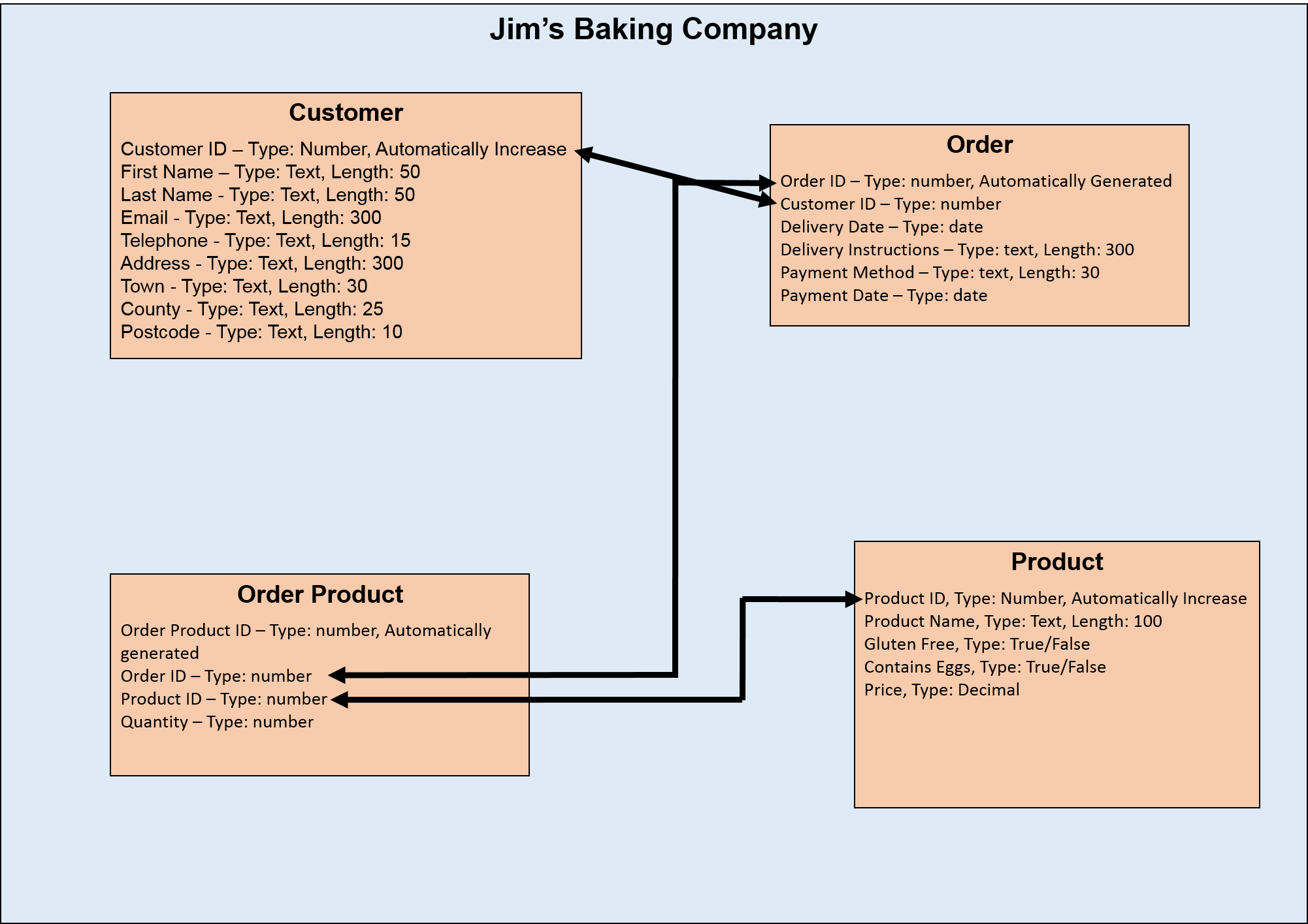
This was Jim’s database the last time we saw it. He had many customers, so his database was set up to allow any of them to make single or multiple orders that can include different varieties of cake.
Business can change a lot in four weeks. Jim has brought out new cakes that he thinks his customers will like, but after an unfortunate incident involving a nut allergy, he realised he needs to list the allergens in each cake. Due to popular demand, Jim has also branched out into biscuits and made ambitious plans to open up in 3 additional locations. As his goods are only going to continue to diversify, he also wants to list his products in a searchable form on his website.
This means extra data, extra complexity and extra functionality. This means changing and upgrading the database.
Let’s start easy. Adding new products could be done with the database above, we just write in new products to the Product table and that’s it, they’re in the database. But what about the accident when someone wasn’t aware of nuts being in a recipe? That was a lucky escape, but Jim wasn’t prepared for it to happen again. The product database table has now changed from this:
To:
Products that were in the database before these new fields were added, will have values of NULL in the new allergen fields. NULL simply means that a value does not exist. As these fields are true or false, we cannot use 0 as a value for no data, as 0 also is interpreted as false.
He is now free to add his new products to the database, safe in the knowledge that his customers will know whether they can eat his cakes.
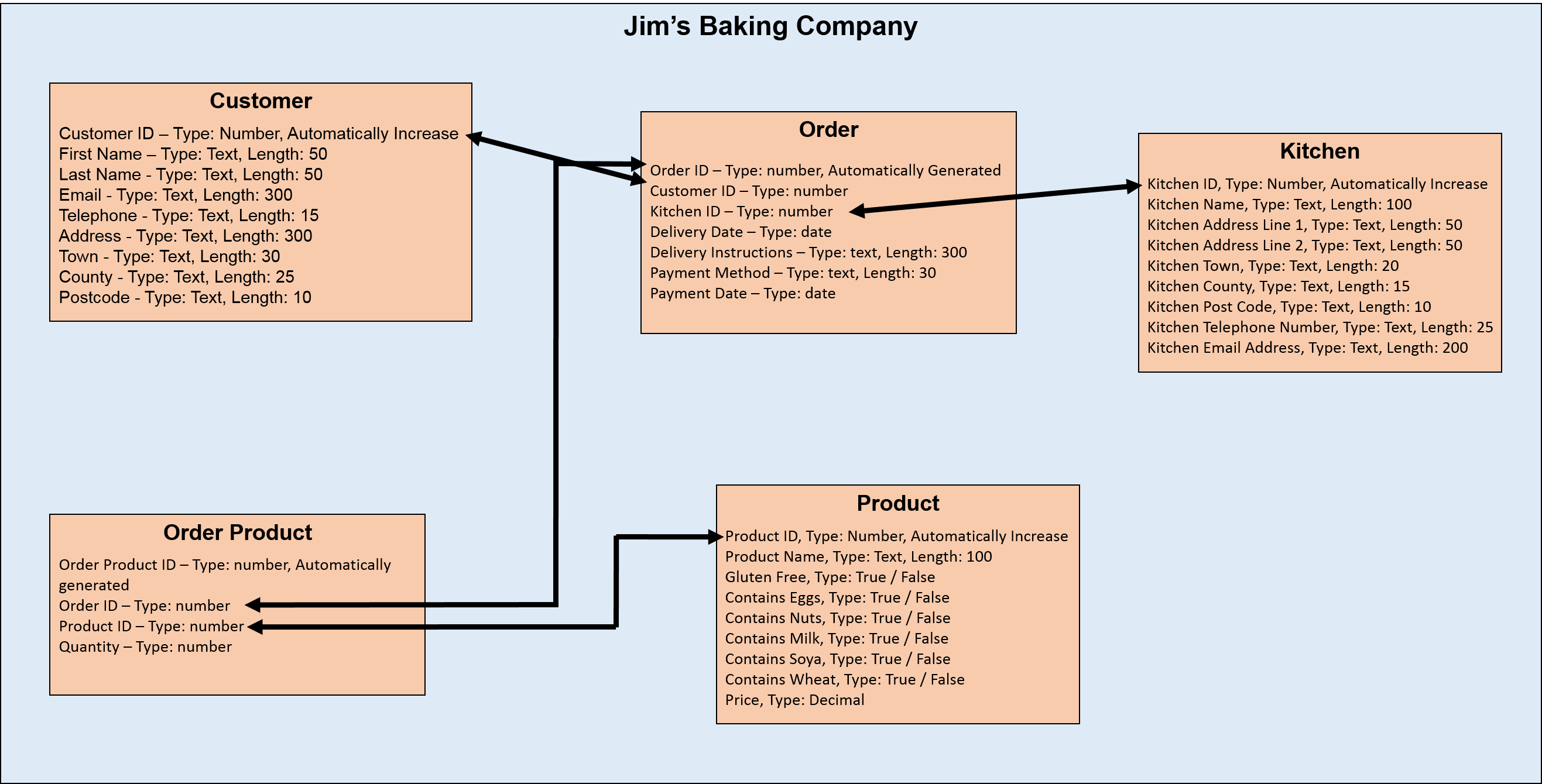
The new kitchens are a big win for Jim. They’re a huge step as he builds his cake-based empire. However, before any of his new locations open he wants his customers to be able to order from any of them.
That means every order for a set of products can be put against one of the locations, and that kitchen will then bake, package and hold onto or send out the order. He’s already decided that the products and prices will be the same at every location.
An initial kitchen table may look like this:
For each kitchen that Jim now opens, all he needs to do is add a new entry into this table. We also need to update the Order table, so that we can assign an order to one of the kitchens. All that requires is adding in the following: Kitchen ID – Type: Number.
Finally, we need to make a link between the Kitchen table and the Order table, so that orders can only be submitted to a kitchen that exists. Our database now looks like the below:
To make ordering as easy as possible, it’s important that Jim categorises what is now a fast growing list of products. To do this, he needs to create custom categories and assign these to each product. So, let’s build a category table:
The category table may look quite simple, but it demonstrates another important database concept known as a recursive relationship. A recursive relationship in this context, is a relationship that rather than linking to another table, links back to its own table. The following is a perfect example of recursive relationships in a database table:
|
Category ID |
Category Name |
Parent Category ID |
|
1 |
Cakes |
NULL |
|
2 |
Chocolate |
1 |
|
3 |
Fruit |
1 |
|
4 |
Candy |
1 |
The first record here, Category 1, is called Cakes. Pretty much everything Jim has made so far would be in this category, but his kitchens bake chocolate cake, sponge cakes, fruit cakes, lemon cakes and so on. He wants each of these in a more specific category than just ‘Cakes’.
In the table above, Jim has created three child categories of the main ‘Cakes’ category. The Parent Category ID number in the third column of this table can only be one of the numbers in the Category ID field that has already been entered into the database, this is what makes the relationship recursive.
So, we can assign Category 2, ‘Chocolate’, to Category 1, ‘Cakes’. This means that there is now a category called ‘Cakes’, with a sub-category called ‘Chocolate’, that would contain any chocolate cake crossovers. The two other categories, ‘Fruit’ and ‘Candy’, have this same relationship.
Following this structure, Jim can create as many subcategories and levels as he wants. The world is his fruitcake right now, but how does his database look?
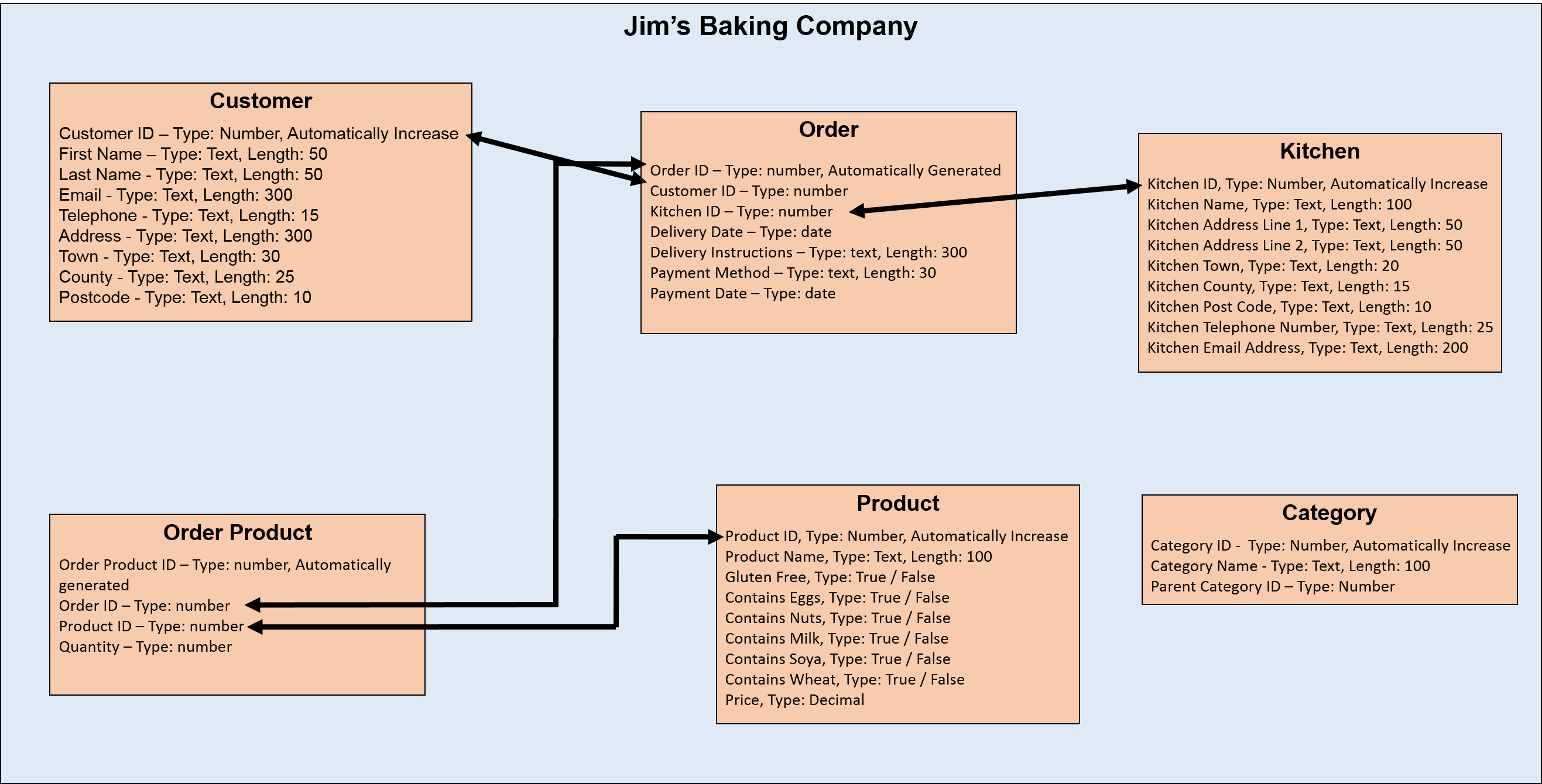
Ah. We have an issue. The Category table has no links to any other table in the database and, with a few exceptions, this should never really happen. We need to be able to link products to one or more categories. There needs to be an intermediary table between Product and Category which determines which products are assigned to which categories.
This Product Category table should look like the following:
Then we can link the Product table to the Product Category table through the Product ID, and the Product Category table to the Category table through the Category ID.
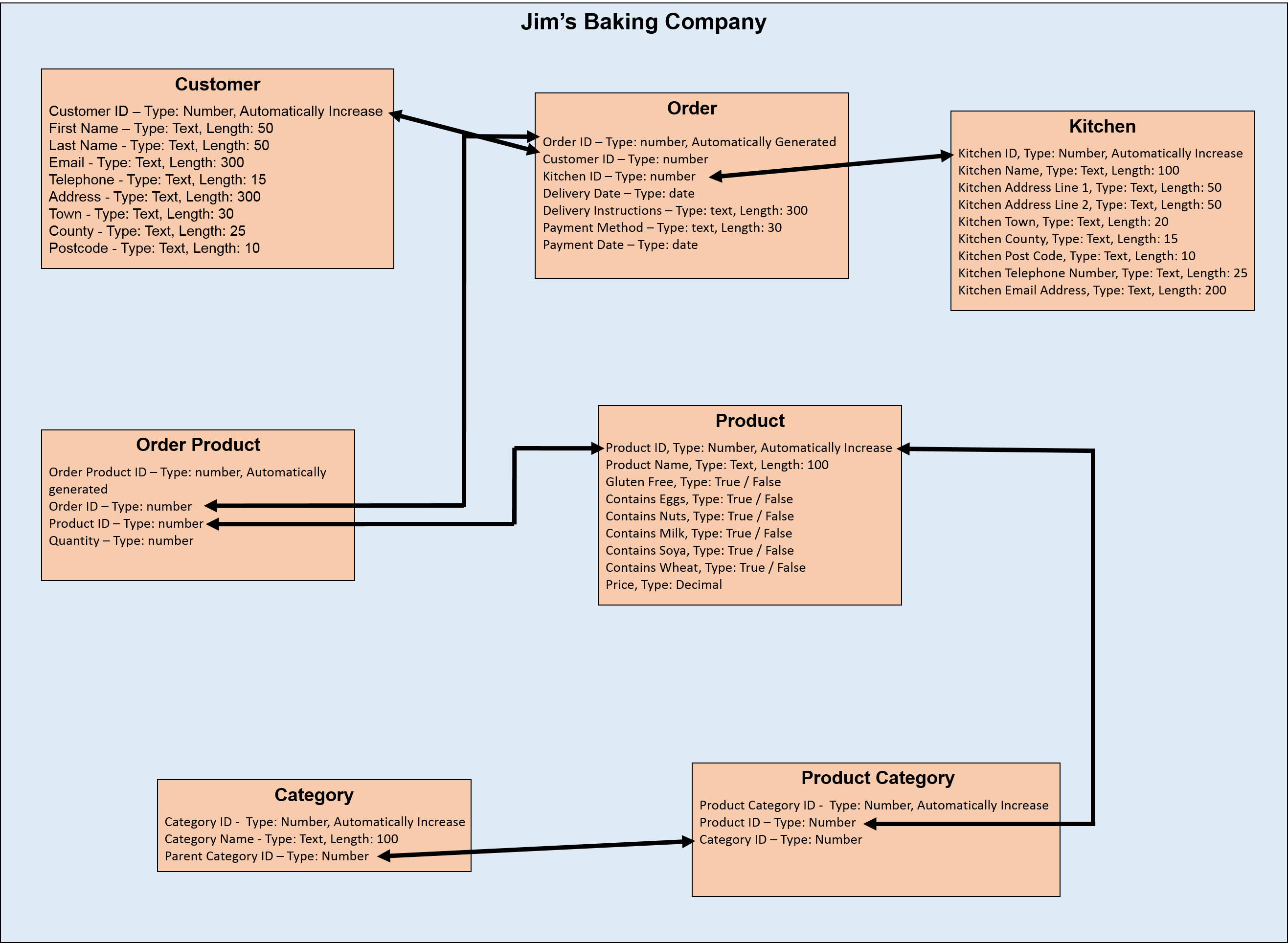
The Product Category table completes the link between all of the tables and means a product can be assigned to any number of categories. Additionally, if Jim assigned a cake to the ‘Chocolate’ category, the structure of the data makes it possible to get the breadcrumb trail back-up through parent categories to see the hierarchy of categories in his database.
Jim has now ventured into biscuits, bourbons, custard creams, jammy dodgers…you name it, he bakes it! With the structure we have now, there is no need to change the database to add a new line of products. Jim can simply add a new category without a parent category called Biscuits, and start creating subcategories, as he sees fit.
In short, Jim’s good to go.
As we said earlier, a lot can change in business, but this structure should support Jim for the next year as he scales up his orders and builds a nice catalogue site to list his products.
Important database advice to go:

Copyright Venn Digital Limited 2023 Cookie Policy Privacy Policy
Site by Venn
