Google Broad Core March 2025 update rolls out
08 Apr, 2025





As the net has developed, web technologies have advanced and website owners want to do more with their sites than ever before. While look and feel may be at the front of users’ minds, in the background the focus is on mass data storage and effective ways of managing that information.
Effectively managing data (or not) can make or break a site. But what is effective data management? How do you store vast, varied information in a sensible manner? To understand, it’s important to strip data storage back to its simplest level, from setting up to scaling up.
“Store it in the database”, “have a look in the database”, “I’ll just check the database and let you know”. Chances are you’ll have heard terms like this hundreds of times before. All data, big or small, needs a sensible storage solution so its information can be stored and a meaning determined. This is where databases come in.
A database is simply a collection of related data. That could be a database for orders, a database for products or a database for your great-uncle Norris’s VHS collection. Using this data efficiently makes all the difference.
Jim runs a cake business. He has a list of cakes he bakes, each of which he sells for a different price. He’s fortunate enough to have a load of customers, many of whom place orders for his cakes to be delivered, but Jim only logs all this on scraps of paper. Let’s just say, he’s not very data savvy. Let’s consider a possible database to help him store these recipes, customers and orders.
Let’s round it off and say that Jim has 240 customers. Each has the standard personal data: name, email, telephone, address and so on. To contain these, we can create the first table in our database called ‘Customer’. Every table in a database should really be a singular name, for example Customer rather than Customers.
In a database table, we create a set of fields appropriate to his data:
Your list of fields would change depending on what data you wanted to store of course, but this is all the data that Jim currently has. Each field has a data type, based on whether it stores text, numbers only, dates, a true or false value and so on. For those fields that are text, a database will usually expect to be told the maximum length of text that can be entered into the field. If we put appropriate data types and lengths against the fields above, we get the following:
Jim now has a table which we can put his list of customers into, a significant efficiency and security upgrade from his handwritten list. But we’ve forgotten one thing…
Databases are strict, and having the ability to find a single piece of data amongst everything is extremely important. To distinguish one record from another, it’s strongly advised that every table you have in your database, contains a unique identifier or key.
This field, the ID number known as a primary key, is often automatically populated by the database when you add in a new record, as a way of keeping every single record unique. This number will only ever come up once, even if you delete the record and re-add it later. Taking Jim’s table above, we can add the following final field:
Jim now has a table in which he can add every customer he has and each individual will be distinguished as completely unique from every one else. No more instances of having to double check he’s got the right Steve Jones or Laura Smith.
The products table follows the same format and thought process as above, except the following fields would likely be present for Jim. Let’s call this table ‘Product’:
Jim can now add all of his products, some information about them and the prices he sells them at. No more undercharging because he can’t find the price for a chocolate cake.
This is where it gets a little more complex and Jim has to think about how he wants to store his data. He needs to consider whether a customer can make an order for multiple products at a time or not. Let’s assume, for the sake of futureproofing, that an order can contain multiple cakes.
A customer, would until now ring up and provide Jim with the following information:
And now knowing this set of requirements for Jim’s data brings up another considering when building a database—the concept of repeated and redundant data.
If we go ahead and create one table with the above information, and then a customer rings up and wants to place an order for 10 different types of cakes, it would take up 10 rows in the database to store all of this. That’s 10 rows of data in this table, just to change the quantity and product each time.
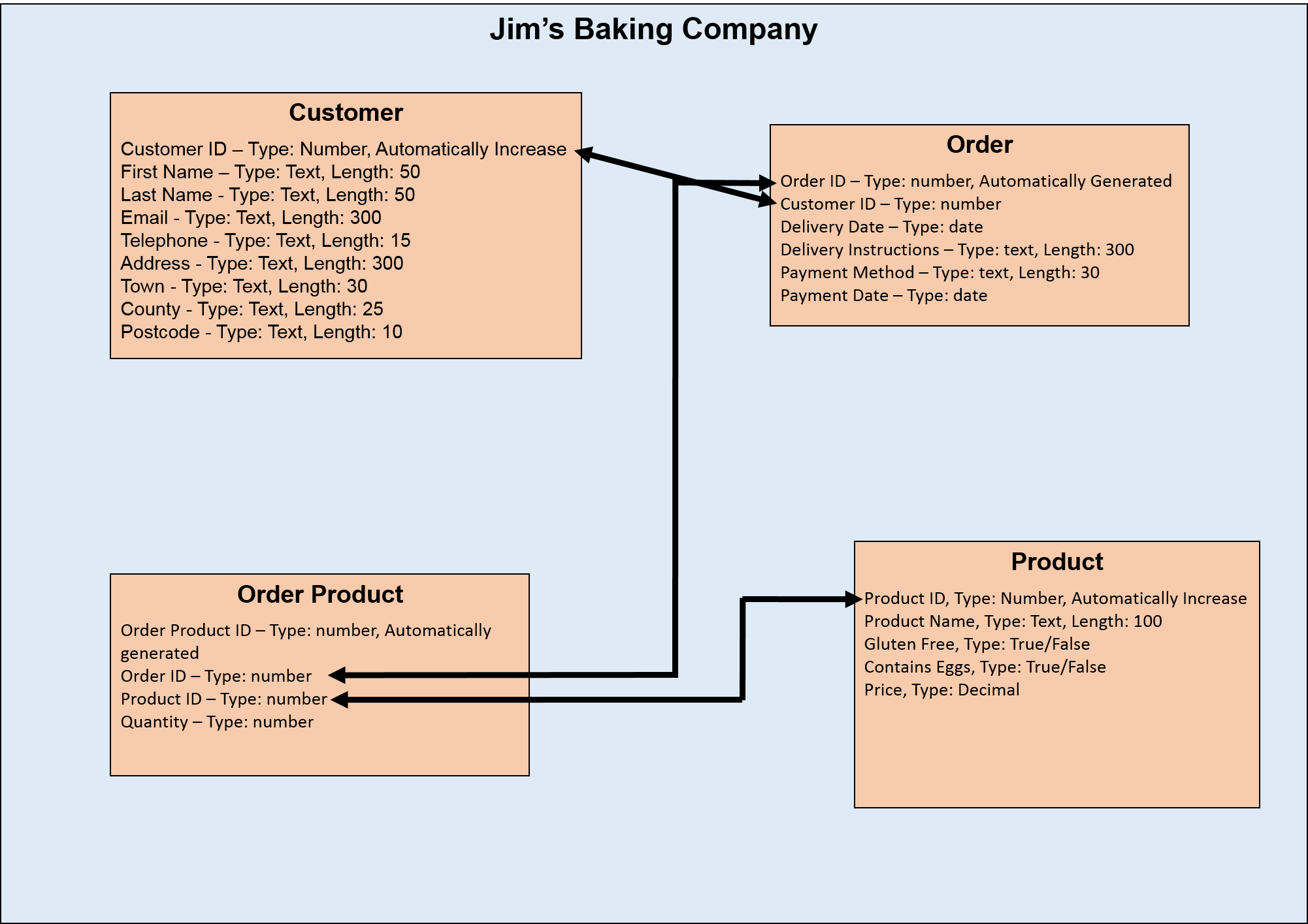
Remember, they are all part of the same order, so the delivery date, instructions and payment methods and dates would be the same. That then becomes 10 rows where these first four fields of data are repeated for no reason other than a poor database structure. Instead, we can split it out into two tables, namely ‘Order’ and ‘OrderProduct’.
In Jim’s case, an order is for a customer and for one or more cakes. So we will now need to make the link between all of our tables so that we know which customer made which order, and for which products.
The Order table would look like this:
Note that this table doesn’t contain any product information. This saves on duplicating the same data multiple times if all Jim wants to do is add different products to an order.
Also, this table contains a field called Customer ID. This is a foreign key, and forms a relationship between this field in the Order table and the Customer ID primary key in the Customer table. This is Jim’s way of making the link between this order and the customer who placed it. This field will store the ID number of the customer who placed the order. This is why every field in every table must be unique.
Now, Jim has an order table to hold his order data, and each order is linked to one customer. This relationship is known as one-to-many, as one customer can make many orders over time. The same relationship can be said for the Order and Order Product table. One order can include many cakes.
So the Order Product table would look like the following:
In this table, we’re really making use of the relationships we have built. The Order ID field will save the order for which this product is on, and the Product ID, will determine which product is added to this order. We also have a quantity field in case someone orders more than 1 of Jim’s cakes at one time!
Jim is now all set to add new customers, create new orders for customers and add more than one product if need be to the same order. His final tables and their relationships look like this:
Important things for setting up an effective database

